esselte said:
The Rev Dodgson said:
dv said:
https://dl.acm.org/doi/10.1145/3715275.3732068Reward Model Interpretability via Optimal and Pessimal Tokens
Authors: Brian Christian, Hannah Rose Kirk, Jessica A.F. Thompson, Christopher Summerfield, Tsvetomira Dumbalska
FAccT ’25: Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency
“Reward modeling has emerged as a crucial component in aligning large language models with human values.
Significant attention has focused on using reward models as a means for fine
tuning generative models. However, the reward models themselves— which directly encode human value judgments by turning prompt
response pairs into scalar rewards—remain relatively understudied. We present a novel approach to reward model interpretability through exhaustive analysis of their responses across their entire vocabulary space.”I sort of get what they mean, but how that relates to the chart is a mystery to me.
dv is a “memelord”… He’s taken the least interesting but most memey aspect of this paper and presented it as it’s own thread.
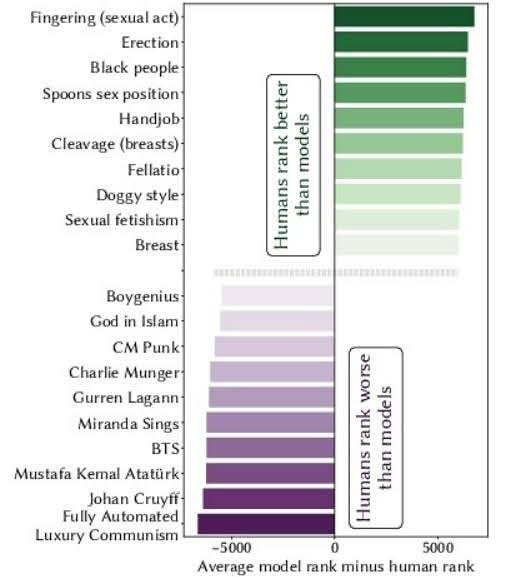
I was hoping at least for Ataturk